
前段时间看到了一篇文章,讲苹果新版的iOS系统做了一个升级,用户有权利选择是否将IDFA标记公开给服务提供商。IDFA标记是用来追踪用户身份的,有了IDFA标记,服务提供商就可以把一个用户产生的各种数据关联起来,从而实现基于大数据的个性化推荐,比如用来做更加精准的广告推送。
假如大部分用户都选择了不公开IDFA标记,代表着以前的广告推荐、内容推荐就都无法正常工作了,这当然让我们的隐私数据得到了更好的保证,但是也让我们丧失了很多个性化推荐提供的便利。
于是我们就在想,能不能用隐私计算来做个性化推荐的系统,保证用户的隐私数据不被任何外界的人看到,同时又能让用户享受到个性化推荐的好处呢?
在上一篇文章中,我们假设了一个企业信息中心的场景。这次就想接着在这个场景下,实现一个针对企业内部内容的个性化推荐系统,帮助企业里面的每个人看到他更感兴趣的内部文档、别人分享的文章等等。
在苹果的场景下,只要用户授权开放了IDFA,我们就可以实现聚合全部数据的内容推荐,而在企业场景下进行内容推荐,由于企业数据是需要严格对外保密的,我们根本不可能把多个企业内部的数据聚合到一起来训练推荐模型,这比个人用户的隐私要求更为严格。
单个企业的内部数据一般是比较少的,只使用一家企业的数据训练出的内容推荐模型,推荐的精准度会非常差。假如有一家企业刚刚开始使用这个系统,在冷启动的时候甚至没有内部的数据来开始训练。这时候,我们如果用隐私计算的技术,实现每家企业的数据都不对外暴露的前提下,联合多个企业的内部数据进行推荐模型的训练,再把得到的模型拿给每一家企业进行使用。可以让每一家企业的推荐质量都得到极大的提升。新加入的企业甚至可以在没有内部数据的情况下, 直接开始享受推荐模型的精准结果。
在这一次的尝试中,我们首先选定了一个传统的推荐系统模型,然后使用横向联邦学习技术来完成保护隐私的分布式模型训练。最后,最重要的部分,因为在联邦学习技术中,需要一个可信第三方来进行多方计算过程的协调,假如这个可信第三方作弊,或者不配合,都会导致整个系统无法正常运作。因此我们使用区块链替代掉了联邦学习中的可信第三方,使得整个系统可以在多个企业组成的P2P对等网络中运行,不受任何单一企业状态的影响。
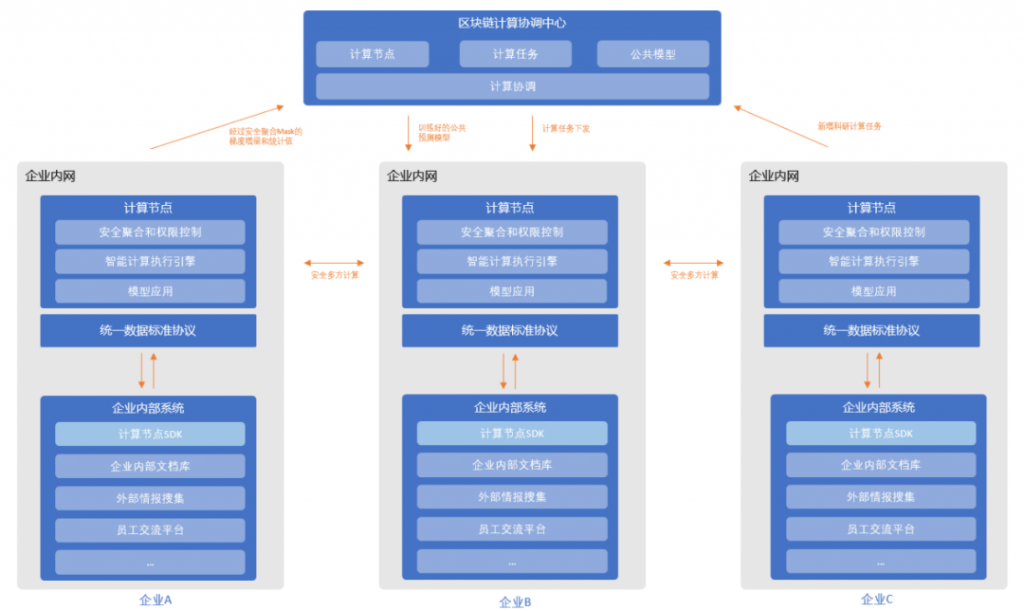
关于区块链和隐私计算的结合,最近一些新的思考是,在涉及多方计算的场景中,一定会涉及到参与者作弊或者是不配合的情况。在以前的每一个具体的算法设计时,都需要将这种情况考虑进去。而针对每一个具体的场景设计不同的算法来解决作弊问题,无疑增大了算法设计的复杂度。区块链其实可以看做是对这一问题的抽象:假如有一个统一的解法,可以让多方算法不用再考虑作弊的问题,而专注在本身要解决的具体问题上,应该可以简化算法设计和系统设计,提高系统运行的效率。
内容推荐模型
内容推荐模型来自KDD 2017年日本雅虎的一篇文章:《Embedding-based News Recommendation for Millions of Users》。推荐系统包含两个子模型,分别为文章编码器和用户编码器,负责对文章和用户的特征进行编码。推荐的过程是计算文章编码和用户编码的内积,内积越大,表明用户越可能点击这篇文章。
文章编码器的结构是一个降噪自编码(Denoising Autoencoder, DAE),DAE中编码器层输出的向量就是文章的编码。文章编码器输入是加入了噪声的文章TF-IDF向量,目标是尝试恢复出原始的TF-IDF向量。文章编码器是以一种自监督的方式来进行训练的,输入和目标都是文章本身,不需要额外的标注,也不需要用户的点击数据。
用户编码器的结构是一个循环神经网络(RNN),RNN中的隐藏状态H就是用户的编码。用户编码器的输入是用户点击过的新闻的编码(来自于文章编码器),目标是使输出的用户编码与用户点击的下一篇文章的编码内积更大。用户编码器的训练数据来自于用户点击文章的历史。
在训练时,用户编码器和文章编码器会分开训练。先使用文章数据训练文章编码器直至收敛,然后使用文章编码器对用户点击过的文章进行编码,再使用用户点击文章的历史训练用户编码器。
文章编码器的训练并不需要使用用户的数据,为了简化问题,对于每个企业内部的文章编码器的训练,我们采用企业内部的文章库直接在本地完成训练。
用户编码器需要用到用户的点击历史,单个企业内部的用户量一般较少,我们就希望能使用其他企业的数据来扩充我们的训练数据。这里我们就引入了横向联邦学习,联合多个企业的数据来训练我们的用户编码器。
横向联邦学习
横向联邦学习中包含两种角色,服务器与客户端。服务器端即是上文所说的可信第三方,负责保存、更新全局的机器学习模型,协调、配置各个客户端对模型进行训练,而客户端就是一家家独立的企业,保存自己产生的隐私数据,使用自己的数据对服务器提供的模型进行训练。
横向联邦学习与传统的机器学习类似,使用类似SGD的方法对模型进行训练,大致流程上是相同的。训练分为很多轮,每一轮都需要:
-
选取数据
-
训练模型
-
更新模型
不断重复这一过程,直至模型达到收敛。
与传统的机器学习相比,不同之处主要有:
-
选取数据:数据不储存在服务器上,而是在客户端上,选取数据就是选取一些客户端提供数据
-
训练模型:模型不在服务器上训练,而是在客户端上进行训练
-
更新模型:模型的梯度会由多个参与训练的客户端提供,需要对梯度进行聚合
因此,在一个轮次中,横向联邦学习的整体流程如下:
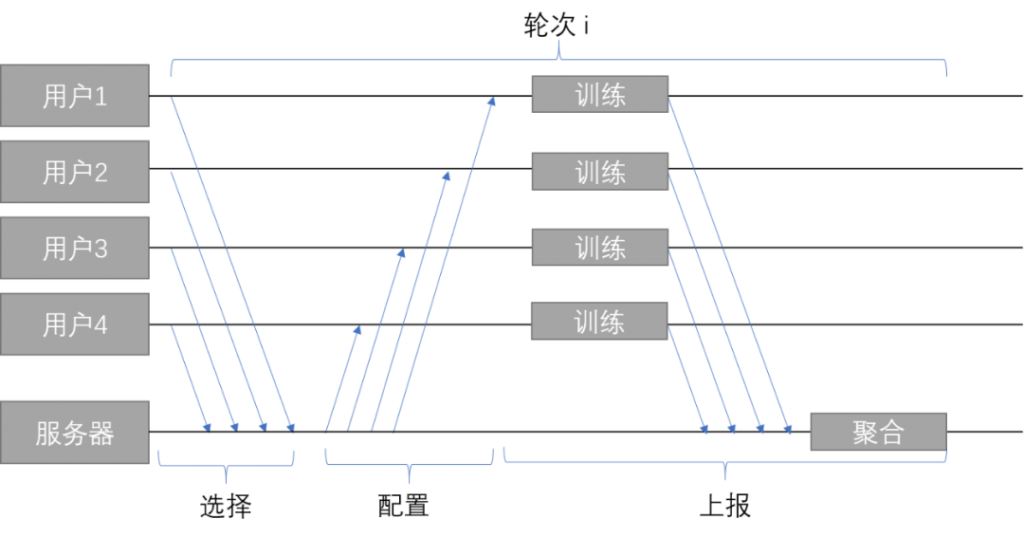
每个轮次共分为三个阶段:选择、配置、上报
选择阶段
选择阶段是一个轮次的开始。每隔一段时间,客户端会检查其是否满足了开始训练的条件时,如果是,客户端就会与服务器建立一个双向的连接,这个连接会用于后续阶段服务器与客户端之间的通信。
服务器与客户端建立连接之后,会根据联邦学习的配置,选择接受或是拒绝这一连接。联邦学习中一个轮次中所需要的用户数量有限,并不是越多越好,只要达到了最低的限度即可。服务器会从所有连接的客户端中,随机地挑选出足够的客户端。对于没有被选中的客户端,服务器会向他们发送指令,让其过一段时间再进行连接,然后断开连接。
配置阶段
在选择阶段完成后,服务器会将本轮训练需要的配置,发送给客户端。这些配置包括了执行计划、当前模型的参数、聚合的方法、聚合方法的参数等等。在这里,模型的执行计划包括模型结构的定义、如何读取数据、如何计算模型的梯度等,服务器会把这些方法打包成为一个可执行的格式,供客户端使用。
上报阶段
客户端将收到的执行计划、模型参数加载进运行时,从客户端本地的数据库中读取数据,进行训练,得到模型的梯度。得到梯度之后,根据配置的聚合方法,将梯度上传给服务器。
服务器收到客户端上传的梯度之后,会根据配置的聚合方法,对梯度进行聚合,求得所有上传梯度的平均值,使用SGD之类的方法,对当前的模型参数进行更新,将新的模型参数持久化到数据库中,供下一轮使用。
安全聚合
多个客户端进行梯度上报、服务器进行梯度聚合的阶段,是整个联邦学习过程中需要重点关注数据隐私的部分,因为这一部分会从客户端发送数据到服务器上。
联邦学习对于这一部分数据上传的隐私保护分为两个部分,首先,从客户端上传的是计算出的梯度增量而不是原始的数据,原始数据无论如何也不会被上报到服务器端,这就对原始数据做出了第一层的保护。
在某些场景下,即使是仅仅上传了梯度增量,对于原始数据的保护也还是不够的。在拥有模型的情况下,外部攻击者有可能通过梯度反推出用于训练的隐私数据,从而造成企业的隐私数据泄露。因此联邦学习中增加了第二层的保护——安全聚合。
安全聚合的设计思路是给原始的梯度加上一个随机的掩膜,生成混淆的梯度。各个客户端通过交换公钥的方式,使得随机生成的掩膜之和为0,这就能保证混淆的梯度之和与原始梯度之和相等。为了应对执行过程中客户端的掉线,各个客户端通过秘密共享的方式,将他们的私钥共享给其他客户端,保证即使掉线,也能去除掉线客户端的掩膜。
为了防止服务器意外获得掉线用户的原始梯度,客户端会再加入第二个随机的掩膜,并将这个掩膜以秘密共享的方式分享出去。服务器在聚合时,会通过共享的秘密,去除掉线客户端的第一个掩膜,以及存活客户端的第二个掩膜,得到原始梯度之和。
安全聚合包含四轮通信过程:
1、客户端将其生成的公钥发送给服务器;服务器将收到的公钥广播给每个客户端
2、客户端将私钥和第二个掩膜进行秘密共享,为每一个客户端都生成一份加密的秘密,发送给服务器;服务器将收到的秘密转发给对应的客户端
3、客户端对原始梯度进行混淆,并将混淆过的梯度发送给服务器;服务器根据这一轮上传的情况,确定最终存活的客户端,和掉线的客户端
4、服务器向存活的用户询问掉线用户的私钥,以及存活用户的第二个掩膜,最终得到存活用户的原始梯度之和
安全的聚合,带来了额外的通信与计算开销,其中计算开销是与用户数量呈二次方关系的。因此,在流程的选择阶段,需要控制连接的用户数量,降低安全聚合的开销;同时在架构上,使用多个子聚合器对客户端进行聚合,降低开销。
安全聚合能够保证在服务器和客户端都按照协议准确地执行时,服务端无法获得用户上传的原始梯度。安全聚合发送给服务器的是经过混淆的梯度,服务器无法得知原始梯度,但是能够从混淆的梯度之和得到原始的梯度之和。同时,安全的聚合能够容忍在运行过程中客户端掉线,只要最后有超过最低限度的客户端存活,就能计算出存活客户端的梯度之和。
移除可信第三方——服务器端
整个分布式模型训练过程的正确完成,非常依赖于服务器端的正确执行。在Google的案例,输入法词组联想功能中,Google是整个功能的设计者,客户端和服务端都由谷歌设计,而输入法的用户只是选择信任了Google。假如Google实际上没有使用联邦学习,用户也无法知道。
在我们的企业场景下,我们更希望能移除对于第三方公司可信的依赖,通过区块链的技术手段实现服务器端的可信,通过智能合约来实现整个服务器端的功能。
横向联邦学习中,服务器主要有以下三个功能点:
1. 储存:储存执行计划、模型的参数、配置等数据
2. 计算:对客户端上传的结果进行聚合
3. 通信:与客户端进行通信,将数据分发给客户端,并从客户端接受数据
对于储存功能,因为执行计划、模型的参数都会很大,区块数据是储存在每一个节点上的,直接将模型储存在区块数据中,会很占用空间。在原本链的研发中,我们实现了可信的链外分布式存储层,通过P2P多备份的方式存储数据,通过链上数据对链外数据进行索引,并且对存储数据的正确性进行校验。通过这样一个链外存储层,我们相当于可以实现在区块链上完成联邦学习需要的存储功能。
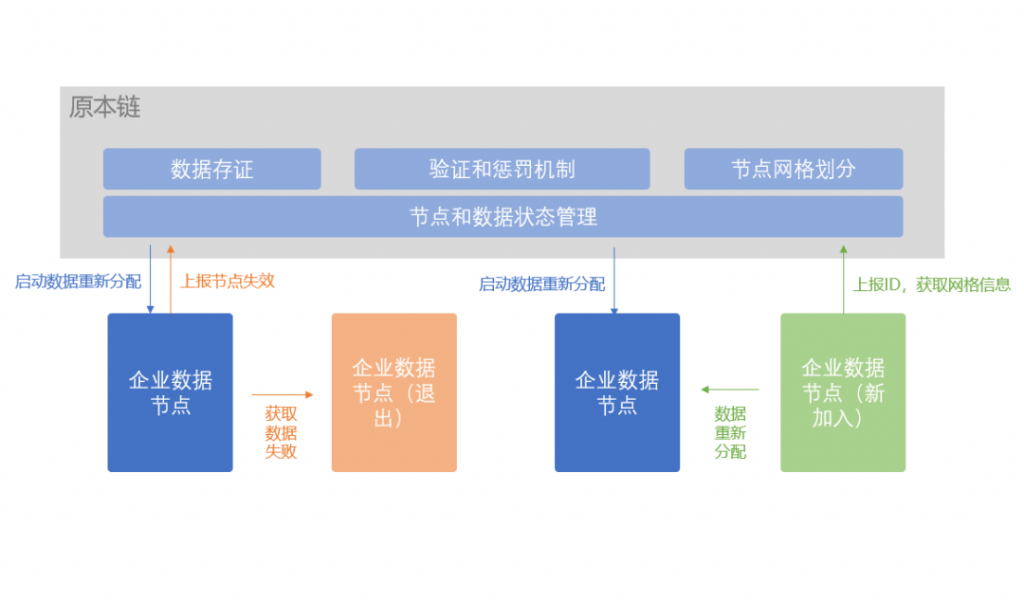
对于计算功能,需要计算的是客户端上传的结果的平均值,计算相对简单,只包含加减乘除等四则运算,因此可以直接在智能合约中实现。但是客户端输出的结果一般是模型的参数的梯度,是矩阵的形式且维度很高,如果智能合约不支持矩阵运算,在智能合约中简单地实现,效率会很低。这里我们还是采用了Layer 2的方法,将实际计算过程转移到链下,在链上提交计算结果,由其他节点进行校验,如果校验失败会触发节点的惩罚机制。
对于通信功能,需要分开讨论。对于客户端上传服务器的数据,智能合约当然是可以实现的。客户端上传数据,就相当于调用智能合约的方法,并向区块链发送一笔交易。对于服务器发送到客户端的数据,智能合约无法像服务器一样发送给各个客户端,需要改为由客户端从区块链拉取数据。当区块链有数据需要发送给客户端时,可以先广播一个特定的事件,通知各个客户端。客户端需要监听服务器的事件,根据收到的事件,执行对应的智能合约的方法,从区块链拉取数据。
除了以上三个功能之外,智能合约还需要实现注册、发布任务、参与任务的功能。
在我们的场景中,无论是提供数据的机构,还是使用数据的机构,都需要先在智能合约中注册,才能参与进来。
注册过的机构,可以通过调用智能合约的方法,发布任务。发布的任务要包含以下几个部分:任务的执行计划、任务的模型参数、使用的聚合方法、所需数据的格式。智能合约会保存这些内容(链上或链下),以供参与方获取。
注册过的机构,可以获取到智能合约上所有发布的训练任务。如果其满足了任务所需要的数据要求,它就可以选择参与这个任务。参与特定的任务,就是调用智能合约的方法,将该机构与参与的任务绑定起来。参与任务之后,该机构就可以参与到任务的训练轮次中,获取任务的执行计划、模型的参数等内容。一个机构可以参与多个任务。
对于发起任务的发起方来说,还需要能够获取参与任务与参与执行轮次的机构列表,以保证当前参与方的数量满足了最低限度。
完整的联邦学习训练过程
1. 任务发起方
假设我们的文章编码器已经训练收敛,且区块链上已经部署了合约,我们现在需要做以下三步:
* 发布任务
我们需要在智能合约上发布我们的训练任务,才能让其他的数据提供方加入我们的训练。在这里,我们需要发布两个任务,分别是训练任务和测试任务。训练任务用来在训练模型,更新参数;测试任务用来测试模型的效果,观察模型的收敛程度。
* 训练模型
在部署完训练任务之后,我们就可以开始训练模型了。
作为发起方,我们首先要检查现在参与这个任务的参与方的数量,只有当参与方数量达到最低的限度之后,才开始发起训练。
我们首先调用智能合约的开始轮次方法,开始一轮训练。我们会等待一个固定的区块时间后,然后调用合约的方法,获取参与这一轮训练的节点。
如果参与的节点数量达到了最低限度,那么就调用配置下发的方法,开始配置阶段。
等待一个固定的区块时间后,调用结束轮次的方法,结束当前轮次,让智能合约聚合训练的结果。监听到轮次结束的事件后,调用合约的方法,获取当前的轮次的计算结果,也就是模型参数的梯度。在本地完成模型参数的更新后,调用合约的更新参数方法,更新智能合约储存的模型参数。在这之后,调用智能合约的开始轮次方法,开始一轮新的训练。
* 测试模型
在传统的机器学习中,我们在训练的同时,需要在验证集上测试当前模型的效果,确定模型的收敛程度。由于我们的用户量较少,单纯使用本地的用户浏览数据作为验证集并不足够,所以可以使用横向联邦学习的方法,在其他参与方的数据上对模型进行测试。
测试任务的执行过程与训练任务大致相同,只是在轮次开始前,调用合约的更新参数方法,更新智能合约储存的模型参数,之后的执行过程与训练模型时一致。任务的轮次结束后,聚合得到的结果就是模型在验证集上的损失。
在测试模型时,我们需要保证用来测试的数据不是训练数据。由于数据读取的方式,是由参与方自己实现的,所以这一点比较难以控制。一种方法是在测试时,选取与测试时不同的参与方;另一种方法在设计读取数据的接口时,预留参数来控制读取数据的范围,例如使用时间范围来作为参数,训练与测试时使用不同的时间范围,不过这一点需要参与方的支持。
2. 任务参与方
对于参与方,需要实现的功能有三个:
* 能运行执行计划的运行时(Runtime)
运行时需要与执行计划的格式相匹配。执行计划有多种格式可选,包括脚本文件、可执行文件、pytorch中的TorchScript、Tensorflow中的Graph等。在这里,我们将执行计划打包为一个Python中的第三方包,参与方只需要有对应版本的Python环境,在使用时安装执行计划的第三方包即可。使用Python第三方包的形式,对于参与方来说,运行时的安装与执行都相对简单,且代码开源,可以审查,没有安全性方面的顾虑。
* 数据读入的接口
参与方需要根据任务的数据格式,以及接口的定义,实现数据读入的接口。
在这里,数据的格式为用户阅读的文章序列{文章1,文章2,文章3,……}。数据读入的接口为:
read_data(timestamp: int, limit: int, offset: int, seq_length: int) -> List[List[str]]其中,timestamp表示数据的起始时间戳,limit表示一次读取的数量,offset表示偏移量,seq_length表示每个文章序列的长度。接口的输出格式为序列的列表。
* 与智能合约交互的逻辑
参与方首先需要先调用智能合约的方法,加入任务。之后参与方监听智能合约的事件,根据事件,执行对应的方法。
当监听到轮次开始事件时,调用智能合约的参与轮次方法,参与这轮训练。当监听到配置下发事件时,调用智能合约的获取配置方法,获取配置、执行计划、模型参数等,调用运行时,运行执行计划。执行计划运行完毕后,根据聚合算法,对运行结果进行处理,之后调用智能的上传结果方法,上传结果。如果监听到了轮次结束的事件,则无论是否上传了结果,直接结束当前轮次的执行。